
Shoggoth-as-a-Service may not survive the rise of AI script kiddies

Since the implosion of web3, the raising of interest rates, and layoffs in FANGs, the tech world has been searching for a new bright spot and has, for now, seized on generative AI.
AI hype -— ever since the coining of the phrase in the 1950’s -— has always of a very unmoored, fantastical variety. There’s no shortage of that this time. As a pundit, you can make up any story about what AI will or won’t be able to do — divorced from any techncial understanding — and, hey, you might as well be right. In product discussions in tech companies, when pitching a feature, including AI can just be a deus ex machina to solve whatever problems the user has – as far as user journeys and mocks go, you can just add a “and then AI happens” slide. It’s hard to cut through it all.
Yet, in these past few months, in tech circles, there has been a near unanimous sense of having witnessed something akin to the iPhone launch, the moon landing, or the first A-bomb, depending on who you talk to.
The inciting moment in this current wave was the launch of ChatGPT late last year —— we’d been hearing about generative AI for a long time, but this was the first time most people got to actually use one firsthand.
So I – and most people I know now – use it just about every day. I have a fraught relationship with it. I send my boss a spec I labored over researching for hours, and he gets back to immediately with “oh, I found one issue — ChatGPT says we should also support X.” I quibble with him and supply some nuanced reason on why I didn’t purposefully didn’t include that, then mutter under my breath “Well, if you love ChatGPT so much, why don’t you marry it?” Then, after some time, I turn to ChatGPT and ask “Did you really tell him that?”

The iPhone comparison is probably the most apt one — the iPhone, like ChatGPT, was just a skillful combination of existing, well-understood technologies in a nice package. But it feels like magic.
This feeling of magic, though exciting, is also disconcerting -— tech shouldn’t feel like magic. It should be understandable, at least to tech people! The feeling of a piece of everyday tech being inscruitible should be reserved for the elderly and Chrissy Teigen, right? Yet many of us who considered ourselves fairly technical and even took courses in things like machine learning and NLP feel strangely confused and left behind.
A great preoccupation of mine in the past few months — for my own sanity and sense of ontological security and, apparently some day, job security — has been trying to strip away that magic. I want to share a bit of my own journey and early conclusions navigating this.
STRIPPING AWAY THE MAGIC
Jailbreaks: The first step for me, as I imagine it was for many, was to start throwing curveballs at ChatGPT, testing its limits — giving it ridiculous creative challenges or trying to trick it out of its tendancy to politely decline certain tasks. After many hours of giving it increasingly outlandish requests and trying to psychoanalyze it like you’re Oliver Sacks, you’re left with a vague sense of it being some kind of alien intellgience — like the ones in Arrivial.
The next step, then, is to start playing with OpenAI’s APIs — this removes the facade of ChatGPT being some kind of agent or a “conversation” with it being something other than just a particular type of document it’s generating. You realize it’s just predicting the next in a sequence of words that happens to begin with something like “The following is a transcript of a conversation between a super-smart, non-racist AI assistant and a human” — and can change the document to tell it to act like anything. Like a simple country lawyer or a guy who gets offended at everything.
Aside from toying with the prompt, you learn how to swap out the underlying model or tweak the “temperature” parameter to make it tipsier (at the risk of anthrophomoprhizing: raising the temperature a little bit is like giving it a shot, too high a full-blown acid trip, too low and it’ll be too clammed up to say anything at all).
You realize immediately how, with any combination of settings and prompts, generative models can go off the deep end and spew word salad. In a clever way, the “conversation” conceit (with a human coming back in every hundred works or so to get it back on track) makes the whole thing work.
AN AI OF ONE’S OWN
The next step down the rabbit hole, for me, was running generative AI models on my own hardware. It’s surprisingly easy to do — recent MacBooks or gaming PCs are good enough to get started. You can even rent out a high-end GPU on the cloud for less than $10/month.
There are many reasons you might do this.
One is privacy and peace of mind. In playing with ChatGPT, there was a fear in the back of my mind that perhaps some day I’d run into someone from OpenAI at a house party in San Francisco and they’d say “Hey, aren’t you the guy who keeps trying to get it to deliver famous speeches in the style of Groucho Marx?1”. And, of course, I’ve always felt uneasy divulging too many of the details of work-related problems I ask it to solve.
Then there’s the pesky safety restrictions put on the cloud versions of these models – seemingly designed as much out of genuine ethnical obligation as much as to avoid the predictable critical press coverage that has enveloped the tech industry in recent years. Yeah, all of that’s gone when it’s your own hardware.
Predictably, then, it seems a great number of the people using Stable Diffusion (for images) and KoboldAI/oogabooga (for text) on their hardware are using them to generate porn and smut, respectively — and, also, oddly, in both cases, DND campaigns, which, if anything, makes it even more of a bullish sign.
Playing around with these open source tools also lets you peek under the hood in ways using a cloud service might not. There are myriad settings to experiment with and new plugins and models every day, both from researchers and outsiders to the field. On forums for these tools, generative AI fanatics —- who did not necessarily come into this particularly versed in AI – discuss finetuning, blending models together, hypernetworks, LoRAs, embeddings, and more.
Playing around with Stable Diffusion is pretty fun — here are some things I made:

With language models, chatting with the same model but with different settings, different sizes/numbers of parameters, or different levels of precision on the weights stored in the GPU is particularly enlightening. Comparing the same conversations with the same character across differently-sized versions of a model made me think of Flowers for Algernon.
The 7B version of Facebook’s LLaMa model, I found, was shockingly good compared to other similarly-sized models, but still had limitations. When asked for restaurant recommendations for Oakland, it recommended restaurants places in San Francisco and Berkeley and was utterly adamnant that they were in Oakland.
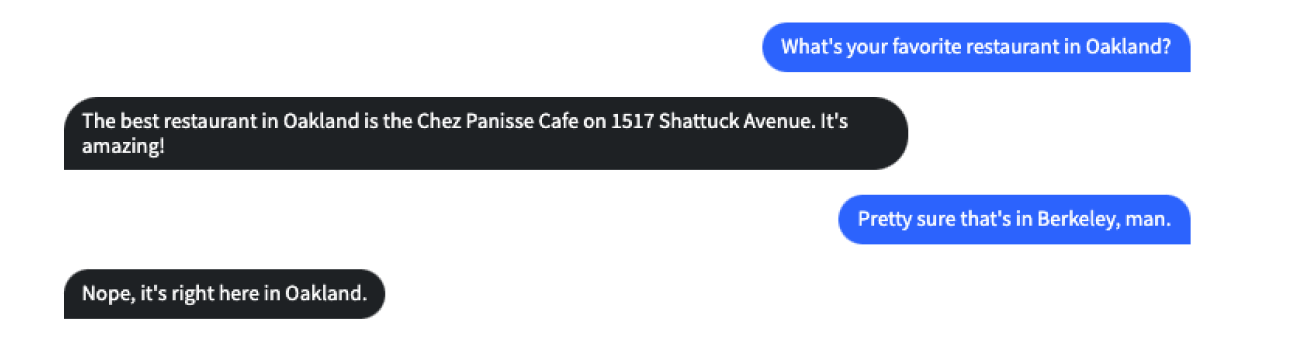
This was a great illustration of the “blurry JPEG of the web” analogy Ted Chiang made in his New Yorker article: In that sized-down version of the model I was running, the embeddings for San Francisco and Oakland were so close in latent space that they may as well be the same city. Llama 7B, clearly, has never had to ride BART. (The 65B version does much better)
GOING BACK TO BASICS
Ultimately I realized, I needed to bone up on some fundamentals I’d missed out on.
Years ago, I’d taken some Coursera courses where you dick around with Kaggle competitions and, say, try to predict what passengers on the Titantic survived with random forest decision trees, but nothing I learned there seemed to be of much use. I’d never really encountered anything — even when I was an engineer, or even when I was working with lots of data — that ever really called for it. During the 2010s, I’d come to realize, there was a transition where more and more machine learning started being done with neural networks (instead of other techniques)2. But my mind was elsewhere — most of the work to be done in software in that decade was just the low-hanging fruit of smartphone adoption — social media, ads, tools for businesses, and so on.
Two resources that I’ve found particularly helpful in the past few months are the Fast.AI “Practical Deep Learning for Coders” course (and accompanying text by Jeremy Howard and Sylvian Gugger) and Andrew Glassner’s “Deep Learning: A Visual Approach”. I’m about halfway through both now.
An apparent mission of Howard and Gugger in the Fast.ai course is dissolving the usual sense of machine learning practitioners being some kind of high priests. They break down a lot of the underlying math and jargon in simple terms and try to help the reader gain enough literacy to read research papers on their own. They also relay countless stories underscoring the point that the field is in its infancy and that ordinary people can make significant contributions to the field with things that only seem obvious in retrospect, like Leslie Smith’s strategy for finding the optimal learning rate in neural networks.
Along the way, the authors share all sorts of tips and tricks. A lot of working with machine learning models, it turns out, is more engineering than science, and, at times, even more dark art than engineering. They show lots of little techniques how to trick the a models into discovering things that you want it to notice. They walk the reader through a lot of experiments with encodings and loss functions.
Another (contradictory) realization I had working through the Fast.ai cirriculum is that, while you get the sense of the field still being new and fundamental discoveries possible, it’s also more possible than ever to stand on the shoulders of giants. Some chapters deal with, for instance, fine-tuning existing models and using transfer learning — like, training the upper layers of the ResNet CNN to recognize different breeds of dogs, while relying on its lower layers to recognize things like, presumably, fur and eyeballs. Modern machine learning libraries also take away a lot of friction — though the book goes over all the underlying theory, it is possible to get a great deal done without being totally confident in one’s knowledge.
Glassner’s book has supplemented this in a powerful way: instead of hands-on exercises he relies on well-consturcted thought experiments and visuals that capture the essence of a concept. This one showing how sentence embeddings make sense of meaning sticks out in my mind:

Since I started spending an hour or so every couple days working through these sorts of resources and doing my own experiments, I’ve felt less intimidated and more excited. It makes me feel like I did when I was fourteen and hacking on PHP scripts in the early 00’s. I didn’t know what the hell I was doing, but I learned so much just by fooling around. There was a term for people like me in those days that the tiny (at the time) class of experienced tech people used – “script kiddies.”
A lot of my peers had similar experiences —- we’d, of course, eventually go to school and learn proper computer science — but wouldn’t have had that start otherwise. I’m pretty sure many in the current generation will have a similar experience with ML.
HOW MY THINKING HAS CHANGED
At this point, there are a gajillion product teams doing the laziest thing imaginable with the OpenAI APIs, like making their own agents by feeding it special prompts. Productivity suites like Office, Google Docs, and Notion have all just hooked a big ol’ “Generate” button into their document editors, because apparently everyone wants that now. Startups that previously struggled to address the question of product-market-fit don’t have to – they can pivot to being “AI companies.”
There are lots of people opining about OpenAI being the next big platform — either by powering many future apps under the hood or by even a primary user interface (as with the recently announced ChatGPT plugins). When I worked on the team making chatbots for Facebook Mesenger, this was basically the dream for the “M” assistant. But I’d still maintain that chat is a crappy interface for most tasks, even if the AI part actually works now. And that there are still tons of advances to be had in products with ordinary, conventional, deterministic UIs — the same way nobody had the idea to put wheels on luggage until the 70’s.
A bias my time at Facebook — a company that, in the early expansion of Web 2.0, thought it was a platform but eventually realized that was wholly contradictory with being a content aggregator that sells ads and had to deprecate tons of APIs to the chagrin of developers — makes me think we’re far from seeing OpenAI’s final form. OpenAI’s developer platform has already had major changes. They’ve changed their pricing (albeit discounting it heavily) and even eliminated models. In the future, they can jack up the prices any time they want, or, if they wish, kick people off the platform, go down any time, or make subtle changes in models that have unanticipated effects on developers. Make no mistake, if AI is the next platform, we’re in its Farmville era.
Another way I’m biased from those years is in thinking that OpenAI-like companies will face privacy challenges. They’re doing a good job heading off the predictable finger-wagging that will come around ethics and safety, but don’t seem prepared for the privacy debate. OpenAI has already had one leak. More broadly, as amount of contextual info we give LLMs on our task grows, that, in business settings, it will seem increasingly weird to keep all of that on someone else’s service. There are already startups solving this. Even for personal use, it’s surprising how intimate a relationship people form with AIs and how uninhibited they can be when interacting with them, which also puts centralized services on a collision course with privacy issues.3
This recent tendency, too, to model every possible AI-addressable problem into natural language (so that it might be solved by a language model) seems limiting, too. A popular essay argues text is the universal interface. But to me, this notion still seems like an even huger impedence mismatch than the one we’ve had for years between object-oriented programming and databases. Yes, simple prompt engineering has proven shockingly effective for many tasks, but it also seems possible to do better job even by finetuning an existing language model with information for the task at hand, or even making your own (not necessarily language-based) model from scratch.
Realizing that this stuff isn’t that hard to run and tweak on your own hardware, that the open-sourced generative models aren’t that far behind OpenAI’s (and, at any rate, not for every problem in the world), and that the fundamentals aren’t that hard to learn on your own makes me skeptical of this hypothesized future landscape. It seems hard to imagine that the future of apps will involve a bunch of REST API calls to query someone else’s largely unexplainable, unaccountable, and unspecialized large language models. Especially now that the tools, knowledge, and hardware have proliferated so much.
But the most underlooked impact of the current generative AI explosion — more than what is actually directly possible with these models — is giving so many people a fun and motivating entry point into the field. Regardless of anything OpenAI may do, it seems a certainty that there will be more and more “script kiddies” at every level learning how to customize AI for their own problems, either by tweaking someone else’s models, fine-tuning, or making their own.
Somehow, I’d never spent this time getting into it because, in my usual work, I’d never need to build, say, a recommendation system, ranking algorithm, or fraud detection feature. But being able to tweak the personality of a bot or the artistic style of Stable Diffusion renderings makes it so much more fun and opens your eyes to more possibilities. And playing with these things hands on sparks so many more ideas on things I could do than reading books or watching contrived demo videos.
My fellow script kiddies, I think, will gradually become more literate in the field and come up with their own tailored models for tasks. There will be a kind of Cambrian explosion in AI-backed products as people — probably without PhDs — experimenting with neural networks (instead of explicit algorithms and heuristics) as ways to solve problems. And tons of people finding interesting ways to use these new products with scraps of technical know-how.
But in any event, after years of feeling bored and cynical, I’m excited that something in tech has come along that makes me feel like I’m fourteen again. If you’ve felt confused and intimidated by recent trends, I encourage you to keep digging deeper. Not knowing what the hell you’re doing can be scary but, with the right mindset, also incredibly freeing.
FOOTNOTES
-
“My friends,” Groucho begins in his iconic ‘I Have A Dream’ speech as imagined by ChatGPT, “I come to the Capitol today with a cigar in my hand and a dream in my heart.” ChatGPT declined to do the same but for Larry the Cable Guy, out of respect for Dr. King’s legacy, but the LlaMa base model obliged. ↩
-
The sudden panic in Silicon Valley over AI is not entirely unfamiliar to me. In 2015, when I was living in China and working at Tencent, there was a similar reaction to AlphaGo. That a foreign company could make an AI to play a traditionally Chinese game so well was, as Kai-Fu Lee described, a “Sputnik moment.” Workshops and lectures about AI were swiftly organized company-wide. I rememember folks from the Beijing research office came down to Guangzhou and gave some lectures on things like neural networks that we all attended out of obligation. I don’t know that it made much of an effect on product teams, though. ↩
-
I mean this not only in the sense that, say, some people got attached to their Repklika chatbots, but even in a more casual sense. I refrained, in this essay, from citing all the amazing and clever things that ChatGPT and other LLMs have told me because, for some reason, people sharing this sort of thing is in the same category as people sharing their blurry concert videos, vacation photos, or dreams. It’s interesting to the sharer because it has a piece of them in it, but it’s not inherently interesting to others. ↩
